#kubernetes zookeeper operator
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
Advantages and Difficulties of Using ZooKeeper in Kubernetes

Advantages and Difficulties of Using ZooKeeper in Kubernetes
Integrating ZooKeeper with Kubernetes can significantly enhance the management of distributed systems, offering various benefits while also presenting some challenges. This post explores the advantages and difficulties associated with deploying ZooKeeper in a Kubernetes environment.
Advantages
Utilizing ZooKeeper in Kubernetes brings several notable advantages. Kubernetes excels at resource management, ensuring that ZooKeeper nodes are allocated effectively for optimal performance. Scalability is streamlined with Kubernetes, allowing you to easily adjust the number of ZooKeeper instances to meet fluctuating demands. Automated failover and self-healing features ensure high availability, as Kubernetes can automatically reschedule failed ZooKeeper pods to maintain continuous operation. Kubernetes also simplifies deployment through StatefulSets, which handle the complexities of stateful applications like ZooKeeper, making it easier to manage and scale clusters. Furthermore, the Kubernetes ZooKeeper Operator enhances this integration by automating configuration, scaling, and maintenance tasks, reducing manual intervention and potential errors.
Difficulties
Deploying ZooKeeper on Kubernetes comes with its own set of challenges. One significant difficulty is ZooKeeper’s inherent statefulness, which contrasts with Kubernetes’ focus on stateless applications. This necessitates careful management of state and configuration to ensure data consistency and reliability in a containerized environment. Ensuring persistent storage for ZooKeeper data is crucial, as improper storage solutions can impact data durability and performance. Complex network configurations within Kubernetes can pose hurdles for reliable service discovery and communication between ZooKeeper instances. Additionally, security is a critical concern, as containerized environments introduce new potential vulnerabilities, requiring stringent access controls and encryption practices. Resource allocation and performance tuning are essential to prevent bottlenecks and maintain efficiency. Finally, upgrading ZooKeeper and Kubernetes components requires thorough testing to ensure compatibility and avoid disruptions.
In conclusion, deploying ZooKeeper in Kubernetes offers a range of advantages, including enhanced scalability and simplified management, but also presents challenges related to statefulness, storage, network configuration, and security. By understanding these factors and leveraging tools like the Kubernetes ZooKeeper Operator, organizations can effectively navigate these challenges and optimize their ZooKeeper deployments.
To gather more knowledge about deploying ZooKeeper on Kubernetes, Click here.
1 note
·
View note
Quote
Open Source Definitely Changed Storage Industry With Linux and other technologies and products, it impacts all areas. By Philippe Nicolas | February 16, 2021 at 2:23 pm It’s not a breaking news but the impact of open source in the storage industry was and is just huge and won’t be reduced just the opposite. For a simple reason, the developers community is the largest one and adoption is so wide. Some people see this as a threat and others consider the model as a democratic effort believing in another approach. Let’s dig a bit. First outside of storage, here is the list some open source software (OSS) projects that we use every day directly or indirectly: Linux and FreeBSD of course, Kubernetes, OpenStack, Git, KVM, Python, PHP, HTTP server, Hadoop, Spark, Lucene, Elasticsearch (dual license), MySQL, PostgreSQL, SQLite, Cassandra, Redis, MongoDB (under SSPL), TensorFlow, Zookeeper or some famous tools and products like Thunderbird, OpenOffice, LibreOffice or SugarCRM. The list is of course super long, very diverse and ubiquitous in our world. Some of these projects initiated some wave of companies creation as they anticipate market creation and potentially domination. Among them, there are Cloudera and Hortonworks, both came public, promoting Hadoop and they merged in 2019. MariaDB as a fork of MySQL and MySQL of course later acquired by Oracle. DataStax for Cassandra but it turns out that this is not always a safe destiny … Coldago Research estimated that the entire open source industry will represent $27+ billion in 2021 and will pass the barrier of $35 billion in 2024. Historically one of the roots came from the Unix – Linux transition. In fact, Unix was largely used and adopted but represented a certain price and the source code cost was significant, even prohibitive. Projects like Minix and Linux developed and studied at universities and research centers generated tons of users and adopters with many of them being contributors. Is it similar to a religion, probably not but for sure a philosophy. Red Hat, founded in 1993, has demonstrated that open source business could be big and ready for a long run, the company did its IPO in 1999 and had an annual run rate around $3 billion. The firm was acquired by IBM in 2019 for $34 billion, amazing right. Canonical, SUSE, Debian and a few others also show interesting development paths as companies or as communities. Before that shift, software developments were essentially applications as system software meant cost and high costs. Also a startup didn’t buy software with the VC money they raised as it could be seen as suicide outside of their mission. All these contribute to the open source wave in all directions. On the storage side, Linux invited students, research centers, communities and start-ups to develop system software and especially block storage approach and file system and others like object storage software. Thus we all know many storage software start-ups who leveraged Linux to offer such new storage models. We didn’t see lots of block storage as a whole but more open source operating system with block (SCSI based) storage included. This is bit different for file and object storage with plenty of offerings. On the file storage side, the list is significant with disk file systems and distributed ones, the latter having multiple sub-segments as well. Below is a pretty long list of OSS in the storage world. Block Storage Linux-LIO, Linux SCST & TGT, Open-iSCSI, Ceph RBD, OpenZFS, NexentaStor (Community Ed.), Openfiler, Chelsio iSCSI, Open vStorage, CoprHD, OpenStack Cinder File Storage Disk File Systems: XFS, OpenZFS, Reiser4 (ReiserFS), ext2/3/4 Distributed File Systems (including cluster, NAS and parallel to simplify the list): Lustre, BeeGFS, CephFS, LizardFS, MooseFS, RozoFS, XtreemFS, CohortFS, OrangeFS (PVFS2), Ganesha, Samba, Openfiler, HDFS, Quantcast, Sheepdog, GlusterFS, JuiceFS, ScoutFS, Red Hat GFS2, GekkoFS, OpenStack Manila Object Storage Ceph RADOS, MinIO, Seagate CORTX, OpenStack Swift, Intel DAOS Other data management and storage related projects TAR, rsync, OwnCloud, FileZilla, iRODS, Amanda, Bacula, Duplicati, KubeDR, Velero, Pydio, Grau Data OpenArchive The impact of open source is obvious both on commercial software but also on other emergent or small OSS footprint. By impact we mean disrupting established market positions with radical new approach. It is illustrated as well by commercial software embedding open source pieces or famous largely adopted open source product that prevent some initiatives to take off. Among all these scenario, we can list XFS, OpenZFS, Ceph and MinIO that shake commercial models and were even chosen by vendors that don’t need to develop themselves or sign any OEM deal with potential partners. Again as we said in the past many times, the Build, Buy or Partner model is also a reality in that world. To extend these examples, Ceph is recommended to be deployed with XFS disk file system for OSDs like OpenStack Swift. As these last few examples show, obviously open source projets leverage other open source ones, commercial software similarly but we never saw an open source project leveraging a commercial one. This is a bit antinomic. This acts as a trigger to start a development of an open source project offering same functions. OpenZFS is also used by Delphix, Oracle and in TrueNAS. MinIO is chosen by iXsystems embedded in TrueNAS, Datera, Humio, Robin.IO, McKesson, MapR (now HPE), Nutanix, Pavilion Data, Portworx (now Pure Storage), Qumulo, Splunk, Cisco, VMware or Ugloo to name a few. SoftIron leverages Ceph and build optimized tailored systems around it. The list is long … and we all have several examples in mind. Open source players promote their solutions essentially around a community and enterprise editions, the difference being the support fee, the patches policies, features differences and of course final subscription fees. As we know, innovations come often from small agile players with a real difficulties to approach large customers and with doubt about their longevity. Choosing the OSS path is a way to be embedded and selected by larger providers or users directly, it implies some key questions around business models. Another dimension of the impact on commercial software is related to the behaviors from universities or research centers. They prefer to increase budget to hardware and reduce software one by using open source. These entities have many skilled people, potentially time, to develop and extend open source project and contribute back to communities. They see, in that way to work, a positive and virtuous cycle, everyone feeding others. Thus they reach new levels of performance gaining capacity, computing power … finally a decision understandable under budget constraints and pressure. Ceph was started during Sage Weil thesis at UCSC sponsored by the Advanced Simulation and Computing Program (ASC), including Sandia National Laboratories (SNL), Lawrence Livermore National Laboratory (LLNL) and Los Alamos National Laboratory (LANL). There is a lot of this, famous example is Lustre but also MarFS from LANL, GekkoFS from University of Mainz, Germany, associated with the Barcelona Supercomputing Center or BeeGFS, formerly FhGFS, developed by the Fraunhofer Center for High Performance Computing in Germany as well. Lustre was initiated by Peter Braam in 1999 at Carnegie Mellon University. Projects popped up everywhere. Collaboration software as an extension to storage see similar behaviors. OwnCloud, an open source file sharing and collaboration software, is used and chosen by many universities and large education sites. At the same time, choosing open source components or products as a wish of independence doesn’t provide any kind of life guarantee. Rremember examples such HDFS, GlusterFS, OpenIO, NexentaStor or Redcurrant. Some of them got acquired or disappeared and create issue for users but for sure opportunities for other players watching that space carefully. Some initiatives exist to secure software if some doubt about future appear on the table. The SDS wave, a bit like the LMAP (Linux, MySQL, Apache web server and PHP) had a serious impact of commercial software as well as several open source players or solutions jumped into that generating a significant pricing erosion. This initiative, good for users, continues to reduce also differentiators among players and it became tougher to notice differences. In addition, Internet giants played a major role in open source development. They have talent, large teams, time and money and can spend time developing software that fit perfectly their need. They also control communities acting in such way as they put seeds in many directions. The other reason is the difficulty to find commercial software that can scale to their need. In other words, a commercial software can scale to the large corporation needs but reaches some limits for a large internet player. Historically these organizations really redefined scalability objectives with new designs and approaches not found or possible with commercial software. We all have example in mind and in storage Google File System is a classic one or Haystack at Facebook. Also large vendors with internal projects that suddenly appear and donated as open source to boost community effort and try to trigger some market traction and partnerships, this is the case of Intel DAOS. Open source is immediately associated with various licenses models and this is the complex aspect about source code as it continues to create difficulties for some people and entities that impact projects future. One about ZFS or even Java were well covered in the press at that time. We invite readers to check their preferred page for that or at least visit the Wikipedia one or this one with the full table on the appendix page. Immediately associated with licenses are the communities, organizations or foundations and we can mention some of them here as the list is pretty long: Apache Software Foundation, Cloud Native Computing Foundation, Eclipse Foundation, Free Software Foundation, FreeBSD Foundation, Mozilla Foundation or Linux Foundation … and again Wikipedia represents a good source to start.
Open Source Definitely Changed Storage Industry - StorageNewsletter
0 notes
Text
Google Analytics (GA) like Backend System Architecture
There are numerous way of designing a backend. We will take Microservices route because the web scalability is required for Google Analytics (GA) like backend. Micro services enable us to elastically scale horizontally in response to incoming network traffic into the system. And a distributed stream processing pipeline scales in proportion to the load.
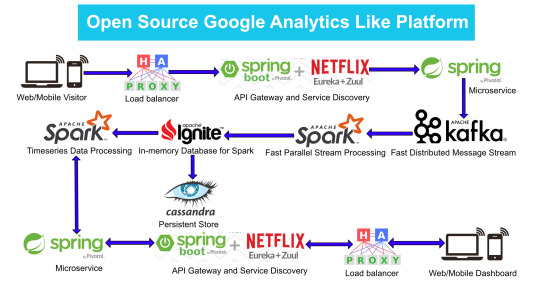
Here is the High Level architecture of the Google Analytics (GA) like Backend System.
Components Breakdown
Web/Mobile Visitor Tracking Code
Every web page or mobile site tracked by GA embed tracking code that collects data about the visitor. It loads an async script that assigns a tracking cookie to the user if it is not set. It also sends an XHR request for every user interaction.
HAProxy Load Balancer
HAProxy, which stands for High Availability Proxy, is a popular open source software TCP/HTTP Load Balancer and proxying solution. Its most common use is to improve the performance and reliability of a server environment by distributing the workload across multiple servers. It is used in many high-profile environments, including: GitHub, Imgur, Instagram, and Twitter.
A backend can contain one or many servers in it — generally speaking, adding more servers to your backend will increase your potential load capacity by spreading the load over multiple servers. Increased reliability is also achieved through this manner, in case some of your backend servers become unavailable.
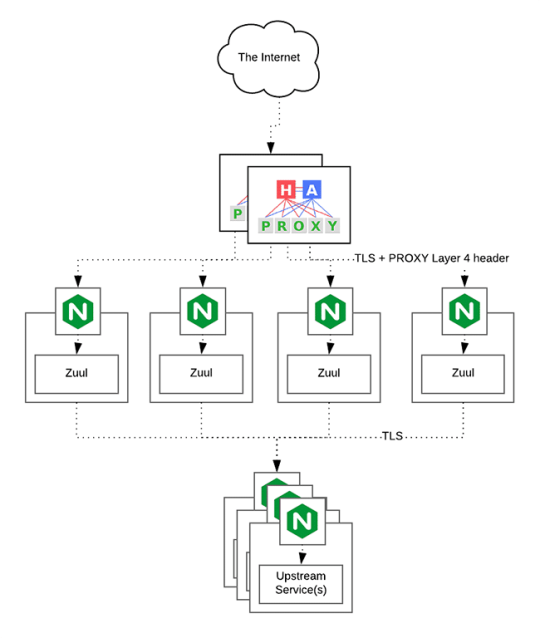
HAProxy routes the requests coming from Web/Mobile Visitor site to the Zuul API Gateway of the solution. Given the nature of a distributed system built for scalability and stateless request and response handling we can distribute the Zuul API gateways spread across geographies. HAProxy performs load balancing (layer 4 + proxy) across our Zuul nodes. High-Availability (HA ) is provided via Keepalived.
Spring Boot & Netflix OSS Eureka + Zuul
Zuul is an API gateway and edge service that proxies requests to multiple backing services. It provides a unified “front door” to the application ecosystem, which allows any browser, mobile app or other user interface to consume services from multiple hosts. Zuul is integrated with other Netflix stack components like Hystrix for fault tolerance and Eureka for service discovery or use it to manage routing rules, filters and load balancing across your system. Most importantly all of those components are well adapted by Spring framework through Spring Boot/Cloud approach.
An API gateway is a layer 7 (HTTP) router that acts as a reverse proxy for upstream services that reside inside your platform. API gateways are typically configured to route traffic based on URI paths and have become especially popular in the microservices world because exposing potentially hundreds of services to the Internet is both a security nightmare and operationally difficult. With an API gateway, one simply exposes and scales a single collection of services (the API gateway) and updates the API gateway’s configuration whenever a new upstream should be exposed externally. In our case Zuul is able to auto discover services registered in Eureka server.
Eureka server acts as a registry and allows all clients to register themselves and used for Service Discovery to be able to find IP address and port of other services if they want to talk to. Eureka server is a client as well. This property is used to setup Eureka in highly available way. We can have Eureka deployed in a highly available way if we can have more instances used in the same pattern.
Spring Boot Microservices
Using a microservices approach to application development can improve resilience and expedite the time to market, but breaking apps into fine-grained services offers complications. With fine-grained services and lightweight protocols, microservices offers increased modularity, making applications easier to develop, test, deploy, and, more importantly, change and maintain. With microservices, the code is broken into independent services that run as separate processes.
Scalability is the key aspect of microservices. Because each service is a separate component, we can scale up a single function or service without having to scale the entire application. Business-critical services can be deployed on multiple servers for increased availability and performance without impacting the performance of other services. Designing for failure is essential. We should be prepared to handle multiple failure issues, such as system downtime, slow service and unexpected responses. Here, load balancing is important. When a failure arises, the troubled service should still run in a degraded functionality without crashing the entire system. Hystrix Circuit-breaker will come into rescue in such failure scenarios.
The microservices are designed for scalability, resilience, fault-tolerance and high availability and importantly it can be achieved through deploying the services in a Docker Swarm or Kubernetes cluster. Distributed and geographically spread Zuul API gateways route requests from web and mobile visitors to the microservices registered in the load balanced Eureka server.
The core processing logic of the backend system is designed for scalability, high availability, resilience and fault-tolerance using distributed Streaming Processing, the microservices will ingest data to Kafka Streams data pipeline.
Apache Kafka Streams
Apache Kafka is used for building real-time streaming data pipelines that reliably get data between many independent systems or applications.
It allows:
Publishing and subscribing to streams of records
Storing streams of records in a fault-tolerant, durable way
It provides a unified, high-throughput, low-latency, horizontally scalable platform that is used in production in thousands of companies.
Kafka Streams being scalable, highly available and fault-tolerant, and providing the streams functionality (transformations / stateful transformations) are what we need — not to mention Kafka being a reliable and mature messaging system.
Kafka is run as a cluster on one or more servers that can span multiple datacenters spread across geographies. Those servers are usually called brokers.
Kafka uses Zookeeper to store metadata about brokers, topics and partitions.
Kafka Streams is a pretty fast, lightweight stream processing solution that works best if all of the data ingestion is coming through Apache Kafka. The ingested data is read directly from Kafka by Apache Spark for stream processing and creates Timeseries Ignite RDD (Resilient Distributed Datasets).
Apache Spark
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams.
It provides a high-level abstraction called a discretized stream, or DStream, which represents a continuous stream of data.
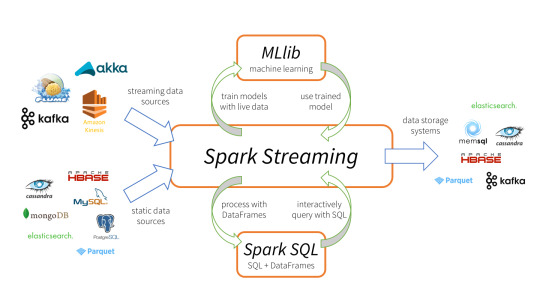
DStreams can be created either from input data streams from sources such as Kafka, Flume, and Kinesis, or by applying high-level operations on other DStreams. Internally, a DStream is represented as a sequence of RDDs (Resilient Distributed Datasets).
Apache Spark is a perfect choice in our case. This is because Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine.
In our scenario Spark streaming process Kafka data streams; create and share Ignite RDDs across Apache Ignite which is a distributed memory-centric database and caching platform.
Apache Ignite
Apache Ignite is a distributed memory-centric database and caching platform that is used by Apache Spark users to:
Achieve true in-memory performance at scale and avoid data movement from a data source to Spark workers and applications.
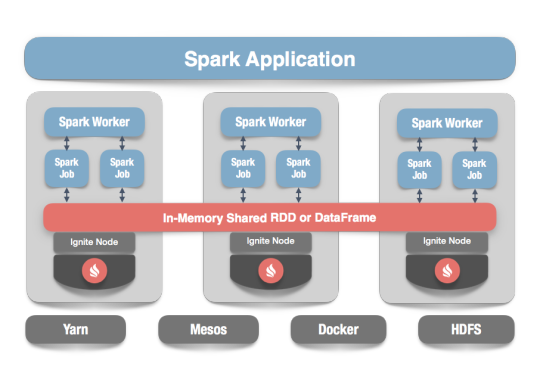
More easily share state and data among Spark jobs.
Apache Ignite is designed for transactional, analytical, and streaming workloads, delivering in-memory performance at scale. Apache Ignite provides an implementation of the Spark RDD which allows any data and state to be shared in memory as RDDs across Spark jobs. The Ignite RDD provides a shared, mutable view of the same data in-memory in Ignite across different Spark jobs, workers, or applications.
The way an Ignite RDD is implemented is as a view over a distributed Ignite table (aka. cache). It can be deployed with an Ignite node either within the Spark job executing process, on a Spark worker, or in a separate Ignite cluster. It means that depending on the chosen deployment mode the shared state may either exist only during the lifespan of a Spark application (embedded mode), or it may out-survive the Spark application (standalone mode).
With Ignite, Spark users can configure primary and secondary indexes that can bring up to 1000x performance gains.
Apache Cassandra
We will use Apache Cassandra as storage for persistence writes from Ignite.
Apache Cassandra is a highly scalable and available distributed database that facilitates and allows storing and managing high velocity structured data across multiple commodity servers without a single point of failure.
The Apache Cassandra is an extremely powerful open source distributed database system that works extremely well to handle huge volumes of records spread across multiple commodity servers. It can be easily scaled to meet sudden increase in demand, by deploying multi-node Cassandra clusters, meets high availability requirements, and there is no single point of failure.
Apache Cassandra has best write and read performance.
Characteristics of Cassandra:
It is a column-oriented database
Highly consistent, fault-tolerant, and scalable
The data model is based on Google Bigtable
The distributed design is based on Amazon Dynamo
Right off the top Cassandra does not use B-Trees to store data. Instead it uses Log Structured Merge Trees (LSM-Trees) to store its data. This data structure is very good for high write volumes, turning updates and deletes into new writes.
In our scenario we will configure Ignite to work in write-behind mode: normally, a cache write involves putting data in memory, and writing the same into the persistence source, so there will be 1-to-1 mapping between cache writes and persistence writes. With the write-behind mode, Ignite instead will batch the writes and execute them regularly at the specified frequency. This is aimed at limiting the amount of communication overhead between Ignite and the persistent store, and really makes a lot of sense if the data being written rapidly changes.
Analytics Dashboard
Since we are talking about scalability, high availability, resilience and fault-tolerance, our analytics dashboard backend should be designed in a pretty similar way we have designed the web/mobile visitor backend solution using HAProxy Load Balancer, Zuul API Gateway, Eureka Service Discovery and Spring Boot Microservices.
The requests will be routed from Analytics dashboard through microservices. Apache Spark will do processing of time series data shared in Apache Ignite as Ignite RDDs and the results will be sent across to the dashboard for visualization through microservices
0 notes
Text
Core Kubernetes: Jazz Improv over Orchestration
This is the first in a progression of blog entries that subtle elements a portion of the internal workings of Kubernetes. In the event that you are essentially an administrator or client of Kubernetes you don't really need to comprehend these points of interest. Be that as it may, on the off chance that you lean toward profundity initially learning and truly need to comprehend the points of interest of how things function, this is for you.
This article accept a working learning of Kubernetes. I'm not going to characterize what Kubernetes is or the center parts (e.g. Case, Node, Kubelet).
In this article we discuss about the center moving parts and how they function with each other to get things going. The general class of frameworks like Kubernetes is normally called compartment arrangement. However, organization infers there is a focal conductor with an in advance arrangement. Nonetheless, this isn't generally an awesome portrayal of Kubernetes. Rather, Kubernetes is more similar to jazz improv. There is an arrangement of performing artists that are playing off of each other to facilitate and respond.
We'll begin by going once again the center segments and what they do. At that point we'll take a gander at a common stream that timetables and runs a Pod.
Datastore: etcd
etcd is the center state store for Kubernetes. While there are imperative in-memory stores all through the framework, etcd is viewed as the arrangement of record.
Snappy synopsis of etcd: etcd is a grouped database that prizes consistency above segment resistance. Frameworks of this class (ZooKeeper, parts of Consul) are designed after a framework created at Google called pudgy. These frameworks are regularly called "bolt servers" as they can be utilized to organize securing a conveyed frameworks. Actually, I find that name somewhat confounding. The information display for etcd (and pudgy) is a basic pecking order of keys that store straightforward unstructured esteems. It really looks a great deal like a document framework. Strangely, at Google, rotund is most as often as possible got to utilizing a dreamy File interface that works crosswise over nearby records, protest stores, and so on. The exceedingly predictable nature, be that as it may, accommodates strict requesting of composes and enables customers to do nuclear updates of an arrangement of qualities.
Overseeing state dependably is one of the more troublesome things to do in any framework. In an appropriated framework it is significantly more troublesome as it gets numerous inconspicuous calculations like pontoon or paxos. By utilizing etcd, Kubernetes itself can focus on different parts of the framework.
Watch in etcd (and comparable frameworks) is basic for how Kubernetes works. These frameworks enable customers to play out a lightweight membership for changes to parts of the key namespace. Customers get advised quickly when something they are watching changes. This can be utilized as a coordination instrument between segments of the appropriated framework. One part can write to etcd and different componenents can promptly respond to that change.
One approach to think about this is as a reversal of the basic pubsub instruments. In many line frameworks, the themes store no genuine client information however the messages that are distributed to those points contain rich information. For frameworks like etcd the keys (closely resembling points) store the genuine information while the messages (notices of changes) contain no interesting rich data. As it were, for lines the themes are basic and the messages rich while frameworks like etcd are the inverse.
The regular example is for customers to reflect a subset of the database in memory and afterward respond to changes of that database. Watches are utilized as a proficient component to stay up with the latest. In the event that the watch fizzles for reasons unknown, the customer can fall back to surveying at the cost of expanded load, organize activity and dormancy.
Approach Layer: API Server
The heart of Kubernetes is a part that is, inventively, called the API Server. This is the main part in the framework that discussions to etcd. Truth be told, etcd is truly a usage detail of the API Server and it is hypothetically conceivable to back Kubernetes with some other stockpiling framework.
The API Server is an approach part that gives sifted access to etcd. Its obligations are generally nonexclusive in nature and it is at present being broken out with the goal that it can be utilized as a control plane nexus for different sorts of frameworks.
The primary money of the API Server is an asset. These are uncovered by means of a basic REST API. There is a standard structure to the majority of these assets that empowers some extended elements. The nature and thinking for that API structure is left as a point for a future post. In any case, the API Server enables different parts to make, read, compose, refresh and look for changes of assets.
How about we detail the duties of the API Server:
Validation and approval. Kubernetes has a pluggable auth framework. There are some worked in systems for both verification clients and approving those clients to get to assets. What's more there are techniques to shout to outer administrations (possibly self-facilitated on Kubernetes) to give these administrations. This kind of extensiblity is center to how Kubernetes is fabricated.
Next, the API Server runs an arrangement of confirmation controllers that can dismiss or adjust demands. These enable strategy to be connected and default esteems to be set. This is a basic place for ensuring that the information entering the framework is substantial while the API Server customer is as yet sitting tight for demand affirmation. While these confirmation controllers are as of now aggregated into the API Server, there is progressing work to make this be another extensibility system.
The API server assists with API forming. A basic issue while forming APIs is to take into consideration the portrayal of the assets to develop. Fields will be included, censured, re-sorted out and in different ways changed. The API Server stores a "genuine" portrayal of an asset in etcd and proselytes/renders that asset relying upon the rendition of the API being fulfilled. Making arrangements for forming and the advancement of APIs has been a key exertion for Kubernetes since right on time in the venture. This is a piece of what enables Kubernetes to offer a tolerable belittling strategy moderately right off the bat in its lifecycle.
A basic component of the API Server is that it likewise bolsters watch. This implies customers of the API Server can utilize a similar coordination designs as with etcd. Most coordination in Kubernetes comprises of a segment keeping in touch with an API Server asset that another segment is viewing. The second part will then respond to changes very quickly.
Business Logic: Controller Manager and Scheduler
The last bit of the perplex is the code that really makes the thing work! These are the parts that arrange through the API Server. These are packaged into particular servers called the Controller Manager and the Scheduler. The decision to break these out was so they proved unable "swindle". On the off chance that the center parts of the framework needed to converse with the API Server like each other segment it would help guarantee that we were building an extensible framework from the begin. The way that there are only two of these is a mishap of history. They could possibly be joined into one major parallel or broken out into a dozen+ separate servers.
The parts here do a wide range of things to make the framework work. The scheduler, particularly, (a) searches for Pods that aren't allocated to a hub (unbound Pods), (b) analyzes the condition of the bunch (stored in memory), (c) picks a hub that has free space and meets different limitations, and (d) ties that Pod to a hub.
Thus, there is code ("controller") in the Controller Manager to actualize the conduct of a ReplicaSet. (As an update, the ReplicaSet guarantees that there are a set number of imitations of a Pod Template running at any one time) This controller will watch both the ReplicaSet asset and an arrangement of Pods in view of the selector in that asset. It at that point makes a move to make/crush Pods with a specific end goal to keep up a steady arrangement of Pods as portrayed in the ReplicaSet. Most controllers take after this sort of example.
Hub Agent: Kubelet
At long last, there is the operator that sits on the hub. This likewise confirms to the API Server like some other part. It is in charge of watching the arrangement of Pods that are bound to its hub and ensuring those Pods are running. It at that point reports back status as things change as for those Pods.
A Typical Flow
To help see how this functions, how about we work through a case of how things complete in Kubernetes.
This grouping outline indicates how a run of the mill stream works for booking a Pod. This demonstrates the (to some degree uncommon) situation where a client is making a Pod straightforwardly. All the more ordinarily, the client will make something like a ReplicaSet and it will be the ReplicaSet that makes the Pod.
The essential stream:
The client makes a Pod through the API Server and the API server composes it to etcd.
The scheduler sees an "unbound" Pod and chooses which hub to run that Pod on. It composes that authoritative back to the API Server.
The Kubelet sees an adjustment in the arrangement of Pods that are bound to its hub. It, thus, runs the compartment by means of the holder runtime (i.e. Docker).
The Kubelet screens the status of the Pod by means of the holder runtime. As things change, the Kubelet will mirror the present status back to the API Server.
Summing Up
By utilizing the API Server as a focal coordination point, Kubernetes can have an arrangement of segments interface with each other in an approximately coupled way. Ideally this gives you a thought of how Kubernetes is more jazz improv than coordination.
0 notes